1 HTTP缓存概述
http缓存是一种利用第一次请求后保存副本其后的请求可以利用缓存响应的技术,它的主要目的为节省流量以及增加资源响应速度。
1.1 HTTP缓存的基本机制
每次如果要获取缓存就得走过一套缓存机制,具体如下图: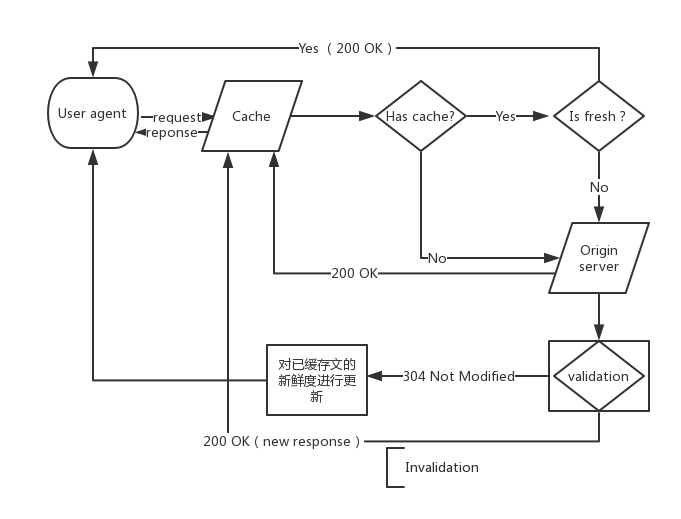
用户发起请求后,会现在缓存中查找是否存在相匹配的缓存,如果没有就向源服务器发起一个请求,如果有的话就会检测这个缓存是否”新鲜”,如果新鲜的话就直接将缓存返回用户,若不新鲜就会向源服务器发送带有验证标识的请求来验证是否可以使用这个已经过期的缓存,若这个验证标识都通过了验证那么就会向发送一个304(not modified)响应,这个响应没有对应的响应体它只会更新缓存的新鲜度,若未通过则重新返回一个带有响应体的响应。
概况起来可以如下:
(1) 接收——缓存从网络中读取抵达的请求报文。
(2) 解析——缓存对报文进行解析,提取出 URL 和各种首部。
(3) 查询——缓存查看是否有本地副本可用,如果没有,就获取一份副本(并将其保
存在本地) 。(4) 新鲜度检测——缓存查看已缓存副本是否足够新鲜,如果不是,就询问服务器是
否有任何更新。(5) 创建响应——缓存会用新的首部和已缓存的主体来构建一条响应报文。
(6) 发送——缓存通过网络将响应发回给客户端。
(7) 日志——缓存可选地创建一个日志文件条目来描述这个事务
note: 上面都是理想情况下比如说没有cache-control的控制,都是可缓存的响应,响应都成功之类。
1.2 缓存基本种类
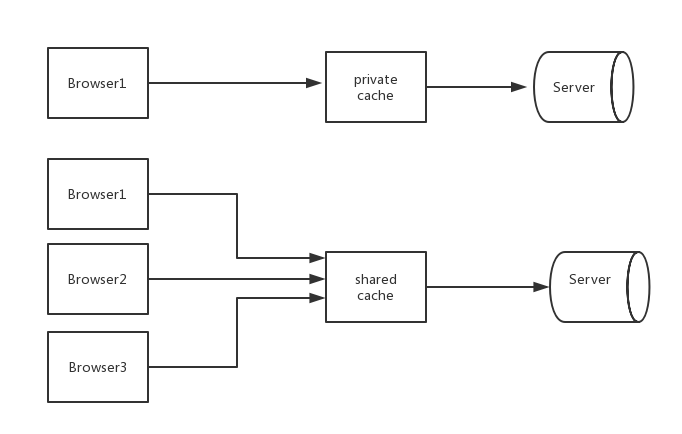
缓存可以被单个用户使用,也可以被成千上万人使用。单用户缓存被称为”私用缓存(private cache)”,一般的浏览器都具有内置的私有缓存,多用户缓存被称为”共享缓存(shared cache)”一般由共享代理服务器来实现或者叫代理缓存(proxy cache)。
- note: 缓存一般情况下都是多级缓存
1.3 控制缓存cache-control
缓存机制由服务端和客服务共同实现默认缓存机制,但是可以通过cache-control与其他的头信息配合修改默认缓存的行为,比如说一般默认缓存GET请求,但是可以通过cache-control:public指令来让POST也可以缓存。具体的指令如下:
1 | //这份图表来自 RFC2616 |
- note:cache-control指令是单向的,请求有响应不一定有,并且在计算如新鲜度的时候优先级不一样。
1.3.1 缓存方式控制
控制缓存方式的有这几种no-cache,no-store,public,priviate
no-cache:
在请求”no-cache”指令暗示着缓存必须在成功的从源服务器上验证后才能使用,在响应中也一样。no-store:
包含这个存储指令暗示缓存一定不能存储请求或响应的任何部分,”一定不能存储”在这个语境中意味着缓存一定不能有意的将信息储存在固态存储器上,同时在信息转发后尽快尽力将其内存中移除。
这个指令并不可靠且没有充分的机制来保障其隐私。特别是在恶意或协商缓存中也许不会识别,并且在和网络通信过程中可能被黑掉。
注意:如果一个请求中包含这个指令并且在缓存中找到匹配响应,那么这个no-store请求指令并不能适用于这个已经存储好的响应。
public:
这个响应指令暗示着任何缓存都可以存储这个响应,哪怕这个响应默认不可缓存,或者只能缓存在私有缓存(包含认证信息的响应只能是私有缓存,默认情况下只有特定响应状态码的响应才能存储)private
这个缓存指令暗示响应消息只能被单个用户存储,一定不能被共享缓存所存储。如果响应默认不能缓存但是有私有存储指令后也可以变得可缓存。
1.4 新鲜度检测
新鲜度检测与使用时期(age)和新鲜生存期(freshness_lifttime)相关,具体如下:
1 | $is_fresh_enough = ($age < $freshness_lifetime); |
age表示的是响应从源服务器响应(或在验证后)之后经历的总时间,这其中包括在因特网和网关中游荡的时间,中间节点缓存存储时间,以及响应在你的缓存停留的时间。具体计算如下
1 | $apparent_age = max(0, $time_got_response - $Date_header_value); |
freshness_lifttime表示缓存生存的时间长度,有服务器响应和客户端请求共同决定,服务器端响应如下
1 | sub server_freshness_limit |
客户端的请求如下
1 | sub client_modified_freshness_limit |
明显最终客户端cache-control的优先级要大一些
1.5 响应过期验证
在缓存文档过期前,缓存任意使用这些响应,而不需和源服务器相关联,但是一旦响应过期缓存的响应就必须与源服务器进行一次验证,验证这些响应是否在之后被修改过。如果修改过就必须返回一份新的响应。
在验证中可以提供以下请求头进行验证:
1 | If-Modified-Since: 'Last-Modified 的值' |
If-Modified-Since包含的是文件上次修改的时间,如果源服务器上次修改的实际小于或者等于这个值时,就返回304并更新缓存新鲜度.
If-Node-Match包含的是响应中的Etag值,这个值是通过哈希计算信息产生的独一无二标记值,如果源服务器的Etag和这个值相同则返回304并更新缓存新鲜度.
如果验证没通过则返回一个全新的响应。
2 如何利用缓存
更多地利用缓存资源,可以提高网站的性能和相应速度。为了优化缓存,过期时间设置得尽量长是一种很好的策略。对于定期或者频繁更新的资源,这么做是比较稳妥的,但是对于那些长期不更新的资源会有点问题。这些固定的资源在一定时间内受益于这种长期保持的缓存策略,但一旦要更新就会很困难。特指网页上引入的一些js/css文件,当它们变动时需要尽快更新线上资源。
web开发者发明了一种 Steve Sounders 称作加速(译者注:revving)的技术[1] 。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
这种方法还有一个好处:同时更新两个缓存资源不会造成部分缓存先更新而引起新旧文件内容不一致。对于互相有依赖关系的css和js文件,避免这种不一致性是非常重要的。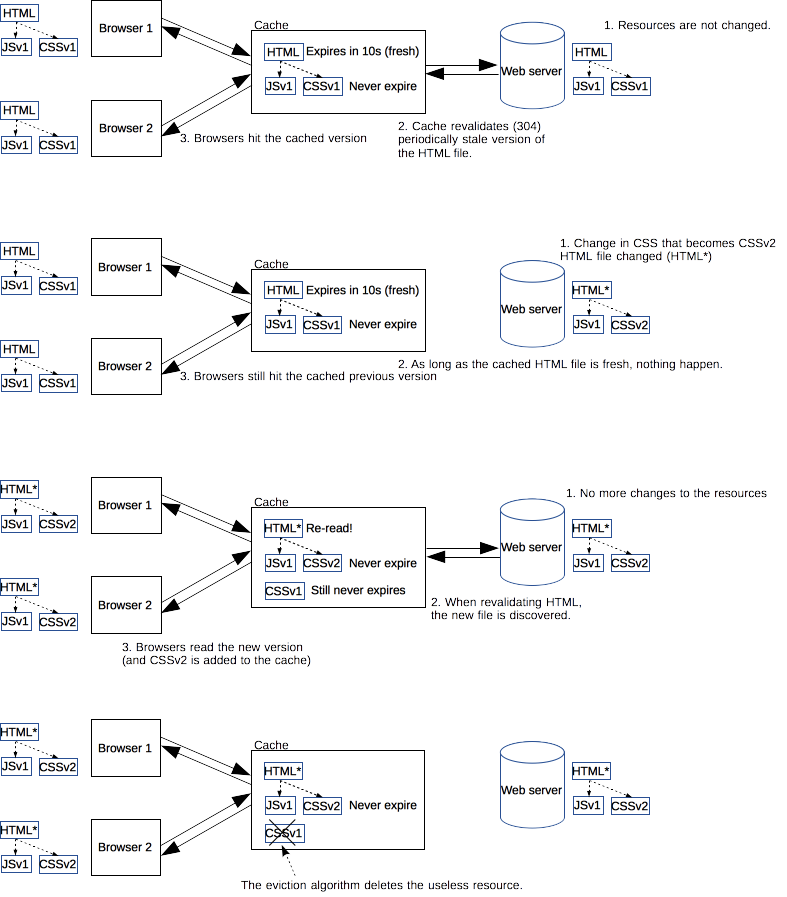
参考: