Unicode的作用
Unicode是一个世界通用的字符集,它定义了全世界大部分书写体系的字符集,并为每一个字符分配了一个独一无二的数字(代码点)。
闭包的定义:A closure is the combination of a function and the lexical environment within which that function was declared.(函数声明时函数内部变量有访问当前作用域链上变量的能力,哪怕变量被函数return出去以后。)
RESTful API 是目前比较成熟和流行的互联网应用程序API设计理论,REST是表述性状态转移(REpresentational State Transfer)的简称。它是一种软件架构风格,设计风格而不是标准,只是提供了一组设计原则和约束条件。
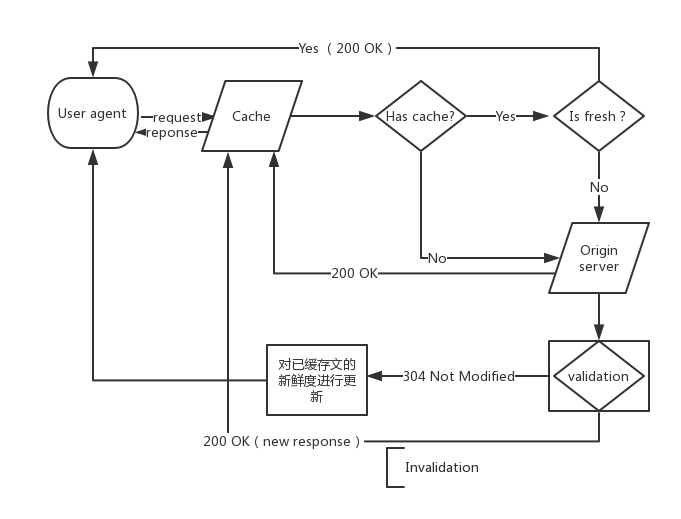
HTTP通常用于分配信息的系统,在这里性能可以通过利用响应存储得到提升,这份文档定义 HTTP/1.1关于缓存和再利用响应消息的部分.
一个HTTP缓存除了包括响应消息的本地存储控制还包括检索,删除,控制存储消息本身.一个缓存了可缓存的响应和等效的普通响应相比使用更少的响应时间和带宽消耗.任何的用户(client)和服务(server)都可以使用缓存,但是被当做隧道(tunnel)的服务不能使用.
共享缓存(shared cache)的响应存储可以被多用户再次利用,通常共享缓存被部署为中介的一部分.相反的私有缓存(private cache)只能被一个用户检查到,通常私有缓存被部署为用户代理的一部分.
在HTTP/1.1中缓存通过再利用先前的响应满足现有请求而达到明显提高效率的目标.一个已存储的缓存被认为”新鲜”(fresh)必须先满足4.2定义部分,那么这个响应可以再利用并且不用”检验”(validation:向源服务器检查看缓存响应是否对于这个请求仍然有效).一个新鲜的响应可以每次重利用因此可以有效的减少延迟的网络管理.当缓存响应不再新鲜是,它也许还可以利用比如通过检验再更新新鲜度(4.3)或者服务源unavailable(4.2.4).
(本来想吐槽下去年才熟练使用Promise但是又要用async-await,但是async-await炒鸡好用,默默流泪)
async-await是promise和generator的语法糖,意在优化promise的写法,简单的说async-await是用来简化pormise写法的,并不是取代关系。
Async放在function关键字前面,await放在Async关键字的函数里,并且最终返回一个promise对象。如下代码所示:
1
2
3
4
5
6
7
8
9
10
11
12async function asyncAwaitDemo(){
const result = await new Promise((resolve, reject)=>{
setTimeout(()=>{
resolve('test')
},200)
})
return result;
}
asyncAwaitDemo().then((r)=>{
console.log('result:',r);
})
// result: test
1.AMD/CMD/CommonJs是JS模块化开发的标准,目前对应的实现是RequireJs/SeaJs/nodeJs.
2.CommonJs主要针对服务端,AMD/CMD主要针对浏览器端,所以最容易混淆的是AMD/CMD:服务器端一般采用同步加载文件,也就是说需要某个模块,服务器端便停下来,等待它加载再执行.浏览器端要保证效率,需要采用异步加载.
3.AMD/CMD区别,虽然都是并行加载js文件,但还是有所区别,AMD是预加载,在并行加载js文件同时,还会解析执行该模块(因为还需要执行,所以在加载某个模块前,这个模块的依赖模块需要先加载完成);而CMD是懒加载,虽然会一开始就并行加载js文件,但是不会执行,而是在需要的时候才执行。
4.AMD/CMD的优缺点.一个的优点就是另一个的缺点, 可以对照浏览。
AMD优点:加载快速,尤其遇到多个大文件,因为并行解析,所以同一时间可以解析多个文件。
AMD缺点:并行加载,异步处理,加载顺序不一定,可能会造成一些困扰,甚至为程序埋下大坑。
CMD优点:因为只有在使用的时候才会解析执行js文件,因此,每个JS文件的执行顺序在代码中是有体现的,是可控的。
CMD缺点:执行等待时间会叠加。因为每个文件执行时是同步执行(串行执行),因此时间是所有文件解析执行时间之和,尤其在文件较多较大时,这种缺点尤为明显。
5.如何使用?CommonJs的话,因为nodeJs就是它的实现,所以使用node就行,也不用引入其他包。AMD则是通过<script>标签引入RequireJs,具体语法还是去看官方文档或者百度一下吧。CMD则是引入SeaJs。
6.commonJS/AMD/CMD/moudle都是动态加载的也是就在代码执行前不知道依赖的,moudle则是静态的,在代码执行之前已经确定了依赖关系。